TL;DR: We analysed thousands of real-world OpenAPI specifications and found that in 76% of modern OpenAPI 3.x specs with a typed data model, JSON Schema is the majority of the file. In the best-known APIs, it routinely exceeds 80%. The schema layer is the substance of every API contract, yet almost no tool is positioned accordingly.
OpenAPI is, by every reasonable measure, the dominant standard for describing HTTP APIs. It is a Linux Foundation project whose founding members include Google, Microsoft, IBM, Capital One, and PayPal. Today the OpenAPI Initiative counts more than 30 corporate members, and the standard is the de-facto contract used by Stripe, GitHub, Mailchimp, Vercel, Slack, Twilio, Zoom, AWS, Azure, Google Cloud, and effectively every other organisation that takes its public APIs seriously.
What is much less well known is that most of an OpenAPI document is not, strictly speaking, OpenAPI at all. It is JSON Schema.
OpenAPI is the chassis, JSON Schema is the engine
OpenAPI provides the structure for describing HTTP endpoints: paths, methods, parameters, responses, security, servers. But the actual work of describing what data flows in and out of those endpoints is delegated to the standard OpenAPI builds on top of: JSON Schema.
In fact, request bodies, response payloads, query parameter types, header constraints: each of these is defined as a JSON Schema. In case you haven’t seen an OpenAPI spec, this is how a trivial one defining a single endpoint looks like:
openapi: 3.1.0
paths:
/pets/{id}:
get:
parameters:
- name: id
in: path
required: true
# This is a JSON Schema
schema:
type: string
format: uuid
responses:
"200":
content:
application/json:
# This is a JSON Schema
schema:
type: object
required: [ id, name ]
properties:
id:
type: string,
format: uuid
name:
type: string
minLength: 1
This layering is not an OpenAPI quirk. When Kin Lane inventoried every API specification stewarded by the Linux Foundation, he found that JSON Schema is the connective tissue of the entire catalogue:
The deeper I looked, the more one thread kept showing up underneath everything else: JSON Schema. OpenAPI uses it. Arazzo and Overlay use it. AsyncAPI uses it. CloudEvents ships a JSON Schema. OSV and SPDX lean on it. The OpenAPI metaschema is JSON Schema. […] JSON Schema is the substrate the other specifications are built on top of.
Let’s measure how big the engine is
We analysed 4,127 real-world API specifications from the APIs-guru/openapi-directory repository, the largest curated dataset of public OpenAPI documents. The dataset is no longer actively maintained, but it remains the de facto industry corpus, still used in the test suites of well-known tools like Speakeasy. The dataset and analysis script is open-source for anyone wishing to reproduce or extend these results.
Across all 4,127 specifications and 17.6 million lines of YAML, 54.3% of the content is JSON Schema, and if we restrict the analysis to OpenAPI 3.x specifications (modern specs), the median rises to 61%. Overall, in 76% of these specifications, JSON Schema is the literal majority of the file. More concretely, we can conclude that: in 76% of modern OpenAPI specifications, JSON Schema dominates the specification.
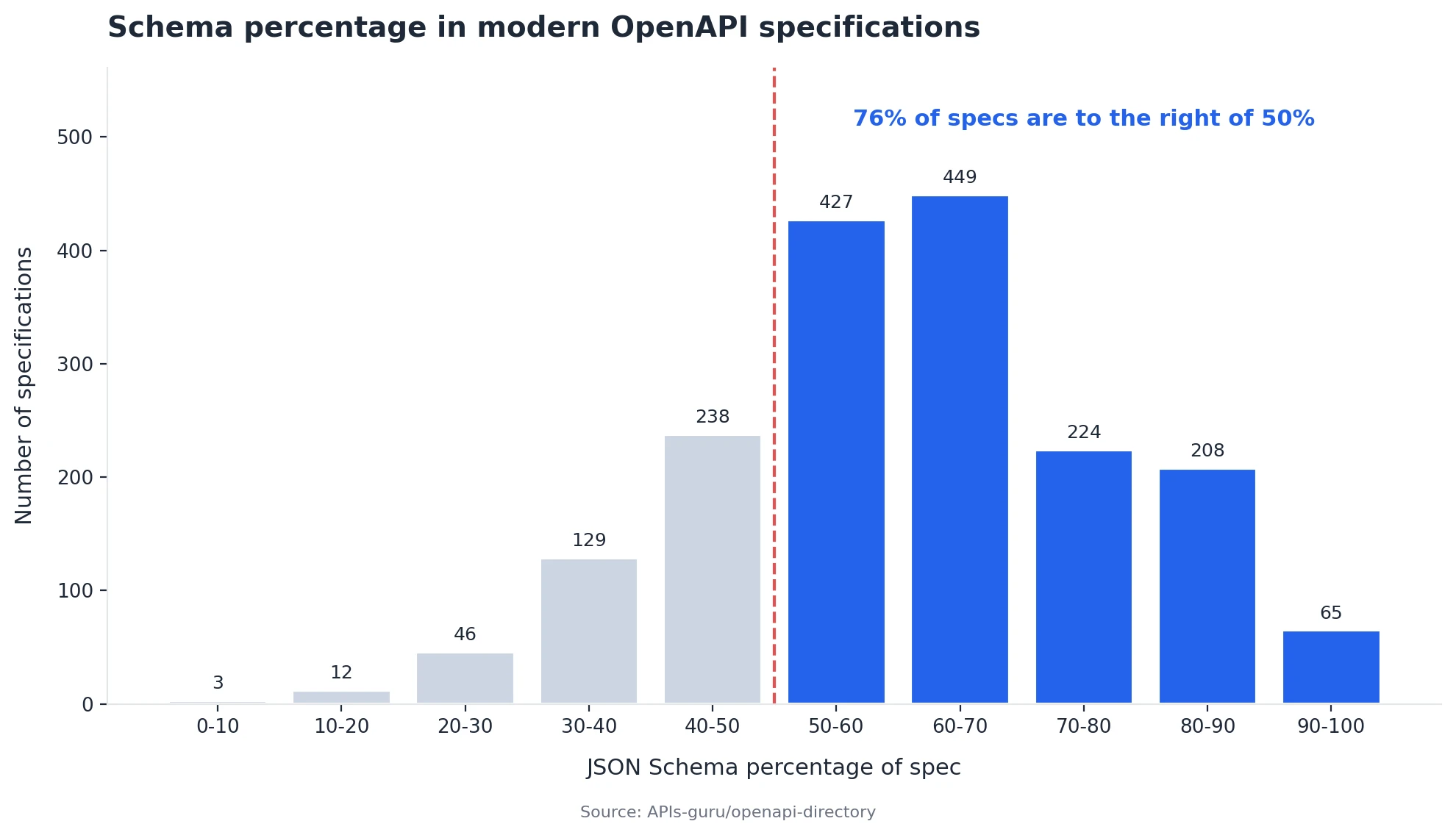
The trend is towards more schema, not less
Comparing Swagger 2.0 to OpenAPI 3.x is interesting. The median Swagger 2.0 spec is 39% schema, while the median OpenAPI 3.x spec is 60%. That is certainly not because the format suddenly enabled more schema content, but because OpenAPI 3.x specifications were typically written more recently. For context, Swagger 2.0 was the dominant format from roughly 2014 to 2017. OpenAPI 3.x took over from 2018 onwards.
The ~21% jump is the industry learning, year over year, that schemas matter.
The same pattern shows up when we segment by API maturity. Specifications with fewer than 10 reusable type definitions have a schema-to-non-schema ratio of around 0.65:1. Specifications with more than 250 type definitions have a ratio of 1.79:1. As APIs grow and stabilise, schema takes over.
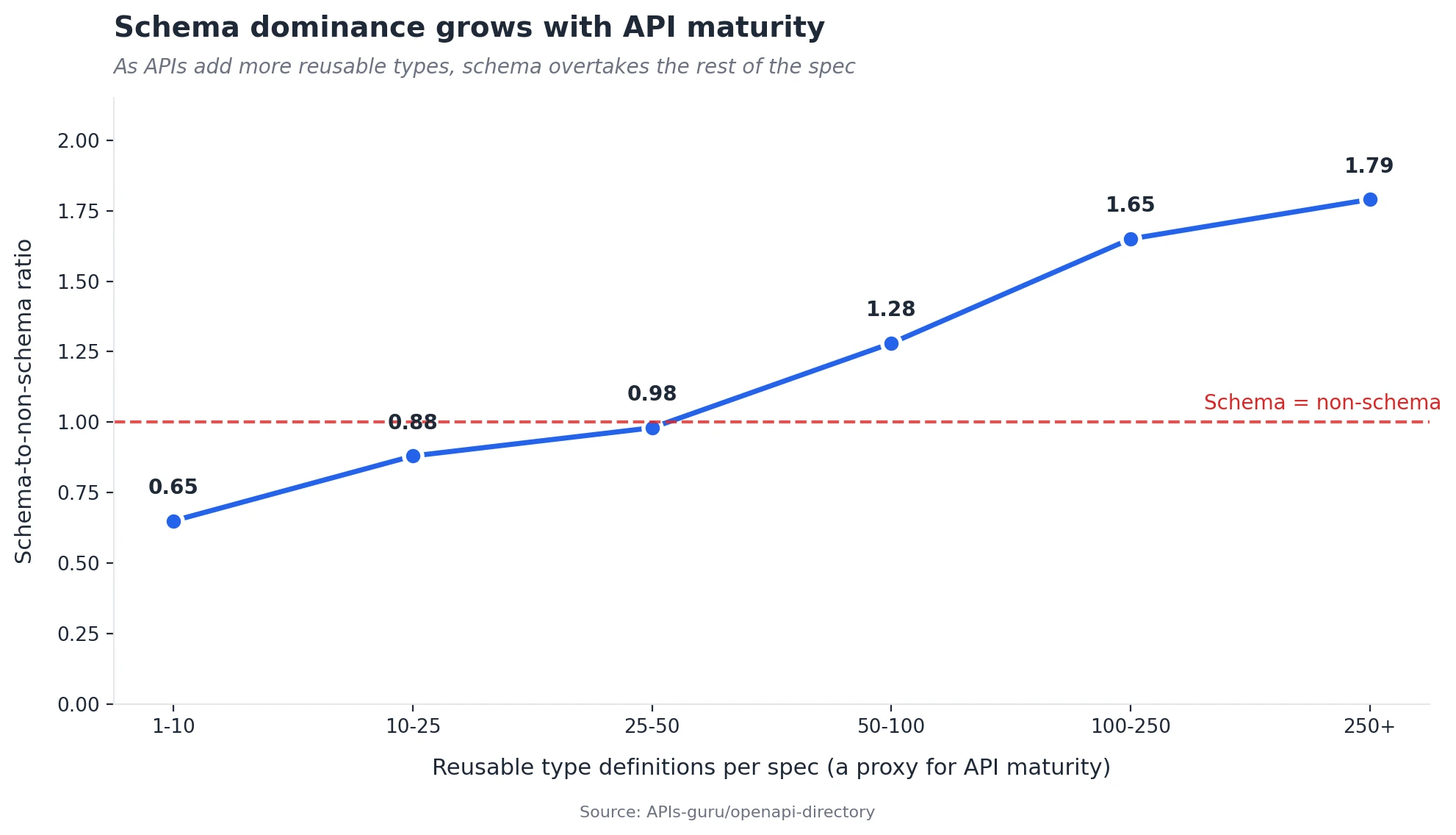
The best-known APIs are almost entirely schema
If you sort the well-known providers in the dataset by how much of their specification is JSON Schema, the top of the list is striking:
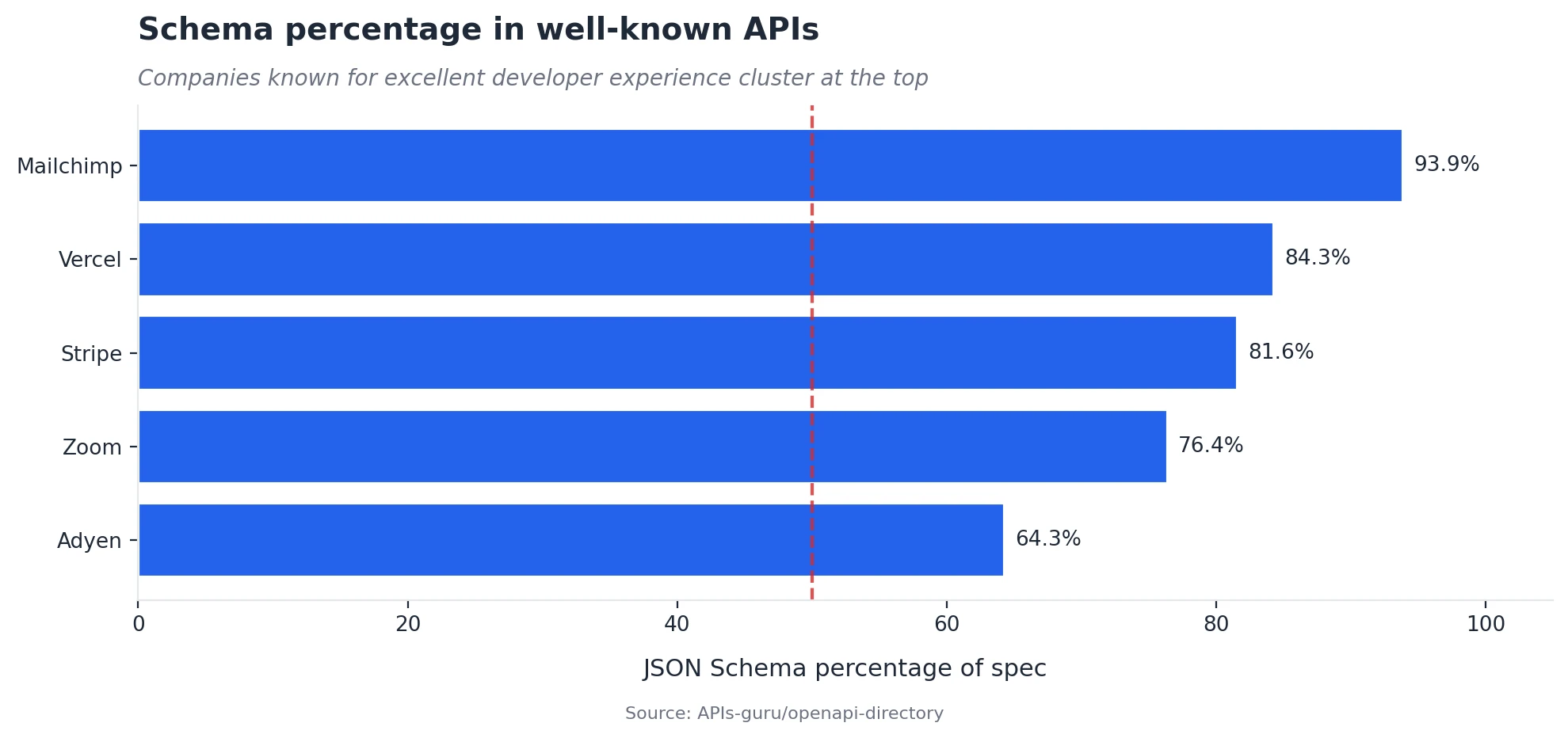
The companies known for taking their developer experience seriously sit at the top of the list.
It is reasonable to conclude that the providers who invest most heavily in API quality also tend to invest more heavily in rich formal type definitions. Likely for the purpose of documentation generation, SDK generation, contract testing, and more.
Two ways the industry hides the schema layer
If JSON Schema is the substance of the API contract, you would expect the tooling ecosystem to be built around it. But It is not. The schema layer loses in two distinct ways: it disappears when tools handle it well, and it goes unnoticed when tools handle it poorly.
When schema work is done well, nobody notices
Take Speakeasy, one of the leading commercial SDK generators in the space. Their product is excellent, and to do its job well it has to do substantial JSON Schema engineering for code-generation purposes. By volume, most of what their generator does end-to-end is schema work, because most of the spec is schema.
And yet the product positions itself as “OpenAPI native”. This is not a Speakeasy critique. The same pattern shows up across most SDK generation, design, and documentation tools: the schema work is being done, often very well, but the product surface presents it as OpenAPI work.
The irony is that the customer is led to think of their work as OpenAPI work, when most of it is schema work. And so they never consider the schema layer as a layer in its own right.
When schema work is done poorly, nobody notices either
Take Prism, a popular tool for mocking and contract-testing APIs against their OpenAPI specs. Doing that job means validating real request and response payloads against the schemas in the spec, which means the validator under the hood is the substance of what the tool does.
Prism ships with AJV, a popular JavaScript JSON Schema validator. The bad news is that AJV is consistently one of the least compliant implementations of JSON Schema around, as proven by the official Bowtie cross-implementation conformance tool. At the time of this writing, AJV lists 254 failures on the version of JSON Schema that OpenAPI 3.1 itself uses.
The practical consequence is more insidious than a broken test. Either Prism rejects payloads that are perfectly valid against your schemas, pushing you to weaken your spec until Prism is happy, or worse, Prism accepts payloads that your schemas should reject, pushing you to ship an implementation that quietly disagrees with what your spec actually says, causing even more subtle drift.
The irony is that Prism is part of SwaggerHub, the flagship platform of SmartBear, the very company that created the Swagger project. If the creators of the wrapper format ship a tool that mishandles the substance inside the wrapper, what hope is there for the rest of the industry?
The schema layer deserves its own infrastructure
If JSON Schema is the substance of your API contract, and if the schema content of your APIs is going to keep growing as your APIs mature, then the schemas deserve their own infrastructure: correct implementations, a cohesive API-first registry, a governance model, a discovery mechanism, and tooling that understands them as semantic objects rather than as opaque sections within a YAML file.
Kin Lane arrives at the same conclusion from the standards side: “there is no reason a CloudEvent’s schema, an AsyncAPI message, and an OpenAPI body could not lean on the same JSON Schema tooling and the same registry patterns”.
The data says the schema layer is already most of your API. The question is whether you treat it that way.