TL;DR: Every major LLM provider (OpenAI, Google, Anthropic, Mistral, xAI, DeepSeek), the Model Context Protocol, and the AI products built on them (agent frameworks and vertical AI APIs) have all converged on the same and only schema language: JSON Schema.
AI is plumbed into APIs, and APIs speak JSON
AI is delivered through APIs. Every major LLM provider exposes its models behind an HTTP endpoint. AI also consumes the world through APIs: tool calls hit REST endpoints and MCP servers expose capabilities over HTTP. APIs sit on both sides of the boundary.
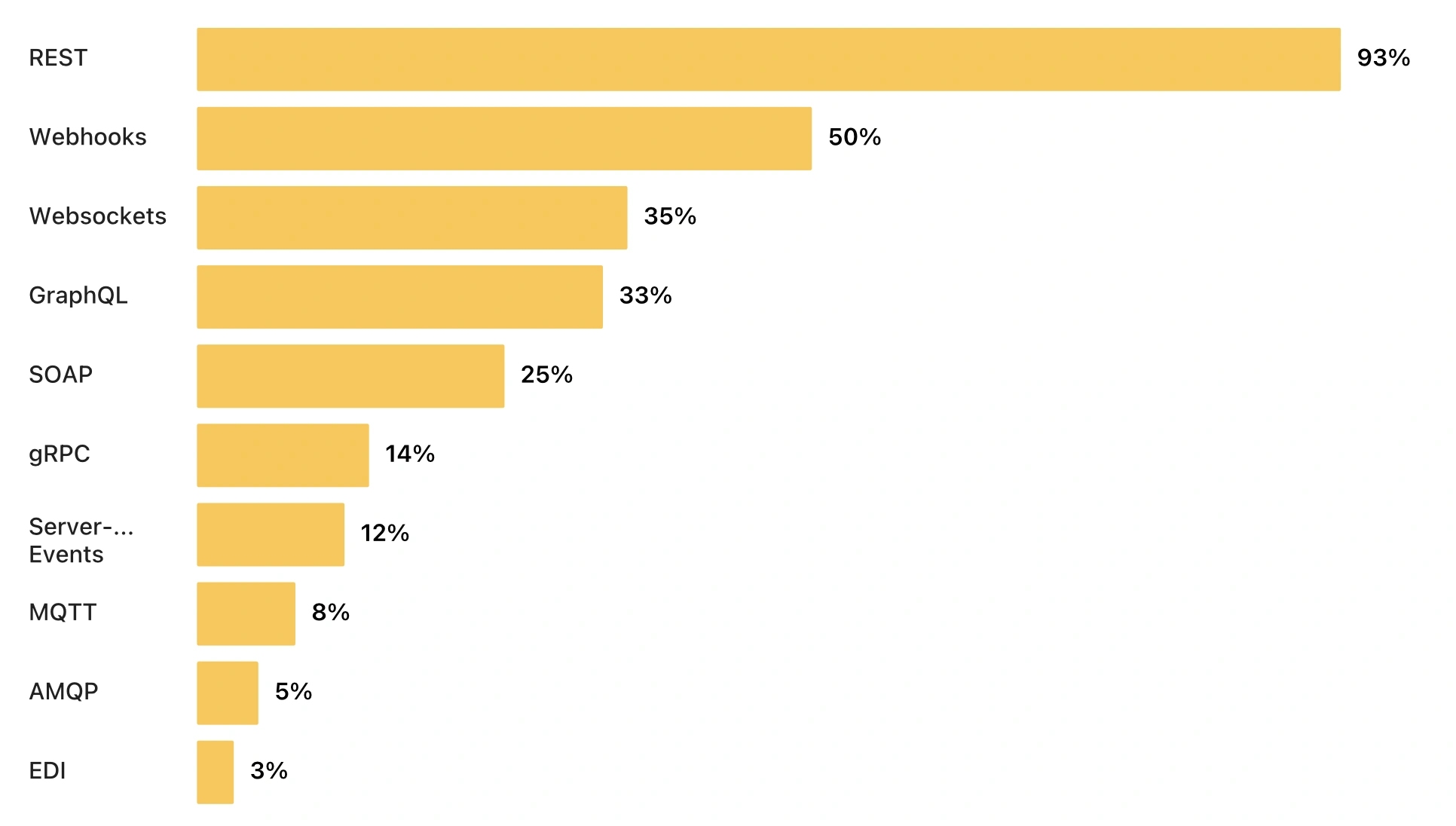
That observation is not contested. Marco Palladino, CTO of Kong, writes: AI traffic is API traffic. Postman’s 2024 State of the API report recorded a 73% year-over-year jump in AI-related API traffic across its platform, with OpenAI alone accounting for 78.5% of it. The 2025 follow-up puts it even more directly: APIs are no longer just powering applications. They’re powering agents. Kin Lane treats AI agents as just another API consumer.
And those APIs speak JSON. In Postman’s 2025 State of the API survey of 5,700+ developers, 93% reported building REST APIs, and REST APIs in practice mean JSON over HTTP.
JSON is what application-layer software uses to move structured data between processes, services, and organisations. The format question was settled before LLMs arrived.
From “please respond in valid JSON, I’m begging you” to schema-enforced generation
If AI is delivered through APIs and APIs speak JSON, then naturally users
wanted LLMs to talk JSON too. In 2023, getting it reliably was a notorious
engineering pain. Workarounds piled up: regex extractors, assistant prefills
("Here is your JSON output: {"), multi-step prompting, repair loops, and even
prompts that politely begged the model to comply. Each had its own brittle
edge cases. Charlie Guo’s Stop begging for
JSON is the museum tour,
and captures perfectly what anyone shipping LLM features had lived through:

The community treated the problem as serious enough to need dedicated infrastructure. jsonformer (~5000 stars on GitHub), an open-source library released in early 2023, opened its README by saying current approaches to this problem are brittle and error-prone. The OpenAI developer forums in 2023–2024 were full of similar threads.
To solve this, OpenAI famously shipped the Structured Outputs feature in August 2024: hand the API a JSON Schema, and the model’s output is guaranteed to validate against it at the token level. No more begging, no more retry loops, no more regex extractors. The pain went from a weekly source of suffering to an API parameter.
The choice of JSON Schema specifically wasn’t accidental. JSON Schema had been the de facto schema language for HTTP APIs for years. OpenAPI, the dominant API description standard, is built on top of it. AI runs on APIs. When OpenAI needed a contract language for the JSON-output problem, they naturally reached for the one API engineers already used.
Structured outputs: six providers, one schema language
Structured outputs proved indispensable beyond chat UIs, for any production pipeline that needed to consume LLM output programmatically. As Julien Chaumond, CTO of HuggingFace, put it: Structured generation is the future of LLMs. Within fifteen months of the first such launch, every major LLM provider had shipped equivalent support. At the time of this writing, all of them support JSON Schema. Literally all of them:
| Provider | Launched | Dialect support | Notes |
|---|---|---|---|
| OpenAI | August 2024 | Unspecified | response_format with json_schema |
| xAI / Grok | December 2024 | 2020-12 and Draft 7 | response_format with json_schema |
| Mistral | January 2025 | Unspecified | response_format with json_schema |
| DeepSeek | August 2025 (Beta) | Unspecified | Through strict-mode function calling |
| Google Gemini | November 2025 | Unspecified (OpenAPI 3.0 lineage) | response_json_schema parameter |
| Anthropic | November 2025 | 2020-12 | output_config.format (and strict tool use) |
As an interesting data point: every provider supports JSON Schema and only JSON Schema on the wire. Not Protocol Buffers. Not Apache Avro. Not GraphQL SDL. Not even Google, despite having invented Protocol Buffers, supports it in their own AI API.
But while every model now technically accepts JSON Schema, it’s not all rosy yet. Dialect commitment is uneven, with only xAI explicitly naming the ones they support. As Ben Hutton, a JSON Schema Technical Steering Committee member, writes: You wouldn’t push your code to a server where you didn’t know what version of the programming language is installed. So why is this OK for JSON Schema?
And even where the dialect is named, each provider supports a different slice
of the language: there are keyword gaps, varied nested-schema depth limits, and
different limitations on advanced features. Even worse, the providers diverge
on which features they support. For example, OpenAI supports recursive schemas
but rejects allOf,
while Anthropic does the opposite.
The meme has evolved. Yesterday’s pain was begging for valid JSON responses. Today, we beg that a valid JSON Schema is actually accepted by every provider.
LLM output constraining is hard
This isn’t JSON Schema’s fault. Constraining an LLM’s output to a schema at the token level is a genuinely hard problem. Each token the model emits has to keep the output valid, and supporting more of JSON Schema’s advanced features (logical operators, dynamic referencing and polymorphism, highly circular schemas, and more) makes it even harder.
And this problem is complex and important enough that an entire research subfield, constrained decoding, has formed around it. Open-source libraries like Outlines (65M+ downloads), XGrammar, and Microsoft’s llguidance made the technique practical at production scale. There is even a published academic benchmark, JSONSchemaBench, built on 10,000 real-world JSON Schemas to evaluate competing implementations.

Even more, the authors of that paper went on to found dottxt, a French startup that raised $11.9M to solve this specific problem. Born from their popular Outlines library, dottxt aims for full LLM JSON Schema coverage and already supports far more of JSON Schema than the major providers do, allowing users to make use of JSON Schema on arbitrary models without feeling the compatibility pain.
Tool calling, and how MCP unified it
LLMs are most powerful when they can connect to other systems: query databases,
hit APIs, run computations, fetch documents. To do this they need a way to
declare I want to call this function with these arguments, and every major
provider had to ship one. Unsurprisingly, they all landed on the same answer:
define the tool’s input as JSON Schema. OpenAI’s
parameters,
Anthropic’s
input_schema,
Gemini’s
function_declarations.
Different field names, identical substrate.
Then MCP (Model Context Protocol) came along to unify it. Announced by Anthropic in November 2024 and built on JSON Schema 2020-12, MCP is to AI agents what OpenAPI is to HTTP APIs: a single shared way to describe tools so any model can discover and invoke them. OpenAI’s official adoption in March 2025 was the inflection point. Monthly SDK downloads jumped from around 8 million to 22 million within weeks. Google DeepMind, Microsoft, Meta, Cursor, Windsurf, JetBrains, Replit, and ChatGPT desktop followed. In December 2025, Anthropic donated MCP to the Linux Foundation, the same body that governs OpenAPI and AsyncAPI.
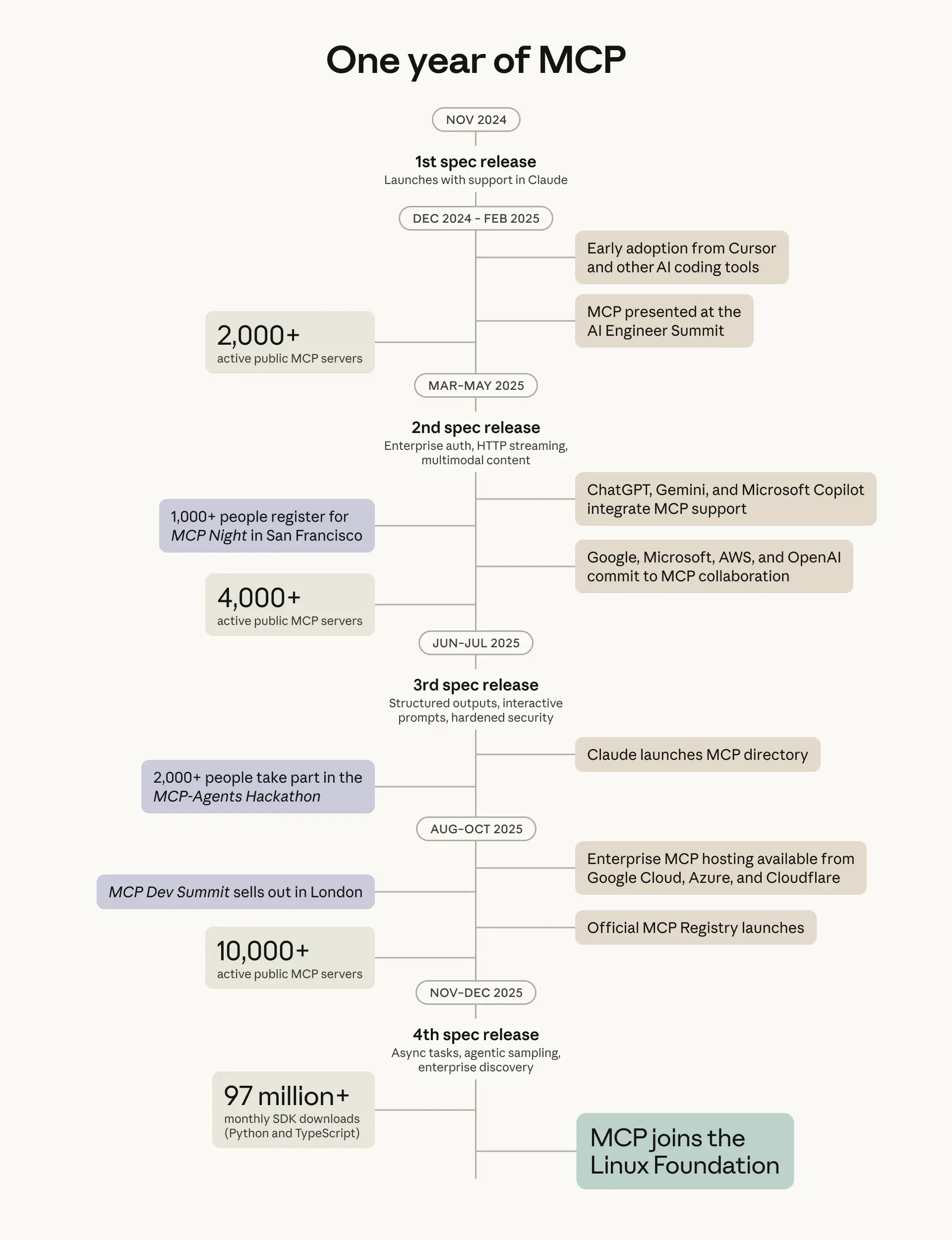
The adoption is substantial. By March 2026, MCP SDKs had reached 97 million monthly downloads, with 13,700+ servers on PulseMCP alone and 300+ MCP clients across editors, chat apps, and enterprise platforms. The business case is concrete. Block reports 50–75% time savings on common tasks for thousands of employees using their MCP-compatible Goose agent. Microsoft’s Sales Development Agent recorded a 15.1% increase in lead-to-opportunity conversion across 61,734 leads. Zapier’s MCP server connects 9,000+ apps with 30,000+ actions.
The entire LLM tool ecosystem now builds on JSON Schema too.
And the whole AI stack speaks JSON Schema
Beyond the LLM APIs and the MCP/tools layer, the JSON Schema foundation extended naturally upward to the AI products built on top. Here is a non-exhaustive list:
- Retab. Document AI platform with
$3.5M pre-seed
backed by Eric Schmidt and the CEOs of Datadog and Dataiku, with
500M+ documents processed. Their SDK literally takes a
json_schemaargument - LandingAI. Andrew Ng’s document AI company. Their Agentic Document Extraction takes JSON Schema as its extraction format, with documented support for standard JSON Schema keywords and format values
- Vapi. Voice AI agent platform. Custom tool
definitions take a JSON Schema as the
parametersfield - AssemblyAI. Speech and transcript
understanding. Their LLM Gateway exposes
response_formatwithjson_schema, OpenAI-compatible - Firecrawl. Web scraping and
extraction. The
schemaparameter takes a JSON Schema describing the structured output to extract from a page - Tavily. Deep research API. The
output_schemaparameter is “a JSON Schema object that defines the structure of the research output”
Above the products sit agent frameworks: the libraries and tools developers use to build programs that compose LLMs with tools, memory, and control flow to decide for themselves which actions to take. Unsurprisingly, every major one uses JSON Schema as the contract between the model and the tools it can invoke:
- LangChain. The dominant Python agent framework
- CrewAI. Multi-agent orchestration
- OpenAI Agents SDK. OpenAI’s first-party agent framework
- Microsoft Semantic Kernel. Microsoft’s framework supporting .NET, Python, and Java
- Mastra. TypeScript-first agent framework
- Vercel AI SDK. The dominant Next.js AI integration layer
- Composio. Tool-integration platform with hundreds of pre-built integrations
None of these products coordinate on which schema language to use. They independently arrived at the same answer to the same problem, making JSON Schema the contract at every layer of the stack.
Even the exception isn’t quite an exception: the A2A hybrid case
You would expect at least one exception to this convergence. Google has every reason to push Protocol Buffers in their AI infrastructure. So when Google designed A2A (Agent-to-Agent), an open protocol for AI agent-to-agent communication, they made Protocol Buffers the “single authoritative normative definition” of the spec.
End of story? Not quite. Look at how A2A actually works on the wire and JSON Schema is still everywhere. Agents communicate using JSON-RPC 2.0 over HTTP. The wire format is JSON, not binary Protocol Buffers. The spec already generates a JSON Schema at build time out of the Protocol Buffers definition, and the authors plan to add an OpenAPI v3 bundle on top for enhanced tooling. You can explore these schemas at schemas.sourcemeta.com.
So even where Protocol Buffers wins as the authoring source, JSON Schema wins as the interoperability substrate. Charlie Holland captures the pattern precisely: “JSON Schema becomes the ‘assembly language’ of schema definitions” and higher-level languages compile down.
The exception confirms the rule: convergence on JSON Schema is not just visible at the LLM layer. It reaches even into the protocols designed to avoid it.
The schema layer deserves its own infrastructure
JSON Schema was first proposed in 2007 as a way to annotate JSON documents. Nobody designed it for AI. It quietly became the dominant API-spec substrate over a decade and a half. The AI industry did not pick JSON Schema. It found that JSON Schema had already been picked, by seventeen years of accumulated convention, and built on top. As Charlie Holland frames it, JSON Schema has become the interface definition language for AI tools.
The implication for anyone building APIs or AI-facing software is direct. Your schema layer is no longer documentation. It is the interface AI systems will use to consume your software. And the demand for that interface is already universal. After auditing 989 Fortune 1000 companies, Kin Lane found zero without an AI signal: The signal floor is non-zero across every industry in the Fortune 1000, including the ones I expected to come up empty. Mining. Tobacco. Specialty retail.
And the next layer of that interface is already taking shape: governance. Portkey’s review of production MCP deployments catalogues the security and trust gaps now surfacing across the ecosystem, and points at a familiar model for closing them: A better reference is JSON-schema-based registries used in major cloud platforms, where structure and validation are enforced.